$$\gdef \E {\mathbb{E}} $$ We then learn a new network $N_{cf}$from scratch on this data. A step-by-step workflow for low-level analysis of single-cell RNA-seq data with bioconductor. In the pretraining stage, neural networks are trained to perform a self-supervised pretext task and obtain feature embeddings of a pair of input fibers (point clouds), followed by k-means clustering (Likas et al., 2003) to obtain initial However, doing so naively leads to ill posed learning problems with degenerate solutions. $$\gdef \vtheta {\vect{\theta }} $$ Following the exposition of Eldad Haber, the loss function we want to minimize is: \[ CNNs always tend to segment a cluster of pixels near the targets with low confidence at the early stage, and then gradually learn to predict groundtruth point labels with high confidence. WebGitHub - datamole-ai/active-semi-supervised-clustering: Active semi-supervised clustering algorithms for scikit-learn This repository has been archived by the owner on topic, visit your repo's landing page and select "manage topics.". Article In model distillation we take the pre-trained network and use the labels the network predicted in a softer fashion to generate labels for our images. If clustering is the process of separating your samples into groups, then classification would be the process of assigning samples into those groups.
The F1-score for each cell type t is defined as the harmonic mean of precision (Pre(t)) and recall (Rec(t)) computed for cell type t. In other words. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Nat Immunol. SciKit-Learn's K-Nearest Neighbours only supports numeric features, so you'll have to do whatever has to be done to get your data into that format before proceeding. Thereby, the separation of distinct cell types will improve, whereas clusters representing identical cell types not exhibiting distinct markers, will be merged together. WebEach block update is handled by solving a large number of independent convex optimization problems, which are tackled using a fast sequential quadratic programming algorithm. Due to the diverse merits and demerits of the numerous clustering approaches, this is unlikely to happen in the near future. S5S8). Whereas, any patch from a different video is not a related patch. Nat Commun. Another example for the applicability of scConsensus is the accurate annotation of a small cluster to the left of the CD14 Monocytes cluster (Fig.5c). Graph Clustering, which clusters the nodes of a graph given its collection of node features and edge connections in an unsupervised manner, has long been researched in graph learning and is essential in certain applications. For this step, we train a network from scratch to predict the pseudo labels of images. The number of principal components (PCs) to be used can be selected using an elbow plot. We have shown that by combining the merits of unsupervised and supervised clustering together, scConsensus detects more clusters with better separation and homogeneity, thereby increasing our confidence in detecting distinct cell types. Here, the fundamental assumption is that the data points that are similar tend to belong to similar groups (called clusters), as determined We used both (1) Cosine Similarity \(cs_{x,y}\) [20] and (2) Pearson correlation \(r_{x,y}\) to compute pairwise cell-cell similarities for any pair of single cells (x,y) within a cluster c according to: To avoid biases introduced by the feature spaces of the different clustering approaches, both metrics are calculated in the original gene-expression space \({\mathcal {G}}\) where \(x_g\) represents the expression of gene g in cell x and \(y_g\) represents the expression of gene g in cell y, respectively.
where \(H({\mathcal {C}})\) is the entropy of the clustering \({\mathcal {C}}\) (see Chapter 5 of [19] for more information on entropy as a measure of clustering quality). PubMedGoogle Scholar. Whereas when youre solving that particular pretext task youre imposing the exact opposite thing. WebHello, I'm an applied data scientist/ machine learning engineer with exp in several industries.
So, embedding space from the related samples should be much closer than embedding space from the unrelated samples. For instance by setting it to 0, each cell will obtain a label based on both considered clustering results \({\mathcal {F}}\) and \({\mathcal {L}}\). Aside from this strong dependence on reference data, another general observation made was that the accuracy of cell type assignments decreases with an increasing number of cells and an increased pairwise similarity between them. CAS Chemometr Intell Lab Syst. WebReal-Time Vanishing Point Detector Integrating Under-Parameterized RANSAC and Hough Transform. The idea is pretty simple: We used antibody-derived tags (ADTs) in the CITE-Seq data for cell type identification by clustering cells using Seurat. Specifically, the supervised RCA [4] is able to detect different progenitor sub-types, whereas Seurat is better able to determine T-cell sub-types. Empirically, we found that the results were relatively insensitive to this parameter (Additional file 1: Figure S9), and therefore it was set at a default value of 30 throughout.Typically, for UMI data, we use the Wilcoxon test to determine the statistical significance (q-value \(\le 0.1\)) of differential expression and couple that with a fold-change threshold (absolute log fold-change \(\ge 0.5\)) to select differentially expressed genes. WebTrack-supervised Siamese networks (TSiam) 17.05.19 12 Face track with frames CNN Feature Maps Contrastive Loss =0 Pos. Pretext task generally comprises of pretraining steps which is self-supervised and then we have our transfer tasks which are often classification or detection. Google Scholar. So we just took 1 million images randomly from Flickr, which is the YFCC data set. Springer Nature. scConsensus: combining supervised and unsupervised clustering for cell type identification in single-cell RNA sequencing data, $$\begin{aligned} NMI({\mathcal {C}},{\mathcal {C}}')&=\frac{[H({\mathcal {C}})+H({\mathcal {C}}') -H({\mathcal {C}}{\mathcal {C}}')]}{\max (H({\mathcal {C}}), H({\mathcal {C}}'))}, \end{aligned}$$, $$\begin{aligned} cs_{x,y}&= \frac{\sum \limits _{g\in {\mathcal {G}}} x_g y_g}{\sqrt{\sum \limits _{g\in {\mathcal {G}}} x_g^2 }\sqrt{\sum \limits _{g\in {\mathcal {G}}} y_g^2}},\end{aligned}$$, $$\begin{aligned} r_{x,y}&= \frac{\sum \limits _{g \in {\mathcal {G}}}(x_g-{\hat{x}})(y_g-{\hat{y}})}{\sqrt{\sum \limits _{g \in {\mathcal {G}}}(x_g-{\hat{x}})^2}\sqrt{\sum \limits _{g \in {\mathcal {G}}}(y_g-{\hat{y}})^2}}. From Fig. $$\gdef \vb {\vect{b}} $$ ae Cluster-specific antibody signal per cell across five CITE-Seq data sets. Fill each row's nans with the mean of the feature, # : Split X into training and testing data sets, # : Create an instance of SKLearn's Normalizer class and then train it. The major advantages of supervised clustering over unsupervised clustering are its robustness to batch effects and its reproducibility. C-DBSCAN might be easy to implement ontop of ELKIs "GeneralizedDBSCAN". In contrast, supervised methods use a reference panel of labelled transcriptomes to guide both clustering and cell type identification.
Next, scConsensus computes the DE genes between all pairs of consensus clusters. curl --insecure option) expose client to MITM. This process can be seamlessly applied in an iterative fashion to combine more than two clustering results. BR and JT salaries have also been supported by Grant# IAF-PP-H17/01/a0/007 from A*STAR Singapore. $$\gdef \unka #1 {\textcolor{ccebc5}{#1}} $$ These pseudo labels are what we obtained in the first step through clustering. $$\gdef \D {\,\mathrm{d}} $$ $$\gdef \Enc {\lavender{\text{Enc}}} $$ A comprehensive review and benchmarking of 22 methods for supervised cell type classification is provided by [5]. b A contingency table is generated to elucidate the overlap of the annotations on the single cell level. The constant \(\alpha>0\) is controls the contribution of these two components of the cost function. (One could think about what invariances work for a particular supervised task in general as future work.). $$\gdef \lavender #1 {\textcolor{bebada}{#1}} $$ Now when evaluating on Linear Classifiers, PIRL was actually on par with the CPCv2, when it came out. [5] traced this back to inappropriate and/or missing marker genes for these cell types in the reference data sets used by some of the methods tested. Thanks for contributing an answer to Stack Overflow!
Webameriwood home 6972015com; jeffco public schools staff directory. Clustering is the process of dividing uncategorized data into similar groups or clusters. However, as both unsupervised and supervised approaches have their distinct advantages, it is desirable to leverage the best of both to improve the clustering of single-cell data. Learn more about bidirectional Unicode characters. In general, talking about images, a lot of work is done on looking at nearby image patches versus distant patches, so most of the CPC v1 and CPC v2 methods are really exploiting this property of images. Lawson DA, et al. It allows estimating or mapping the result to a new sample. What are noisy samples in Scikit's DBSCAN clustering algorithm? The K-Nearest Neighbours - or K-Neighbours - classifier, is one of the simplest machine learning algorithms. $$\gdef \N {\mathbb{N}} $$ Privacy By using this website, you agree to our \min_{U}\mathcal{E}(U) = \min_{U} \left(\text{loss}(U, U_{obs}) + \frac{\alpha}{2} \text{tr}(U^T L U)\right) 39. So you have the image, you have the transformed version of the image, you feed-forward both of these images through a ConvNet, you get a representation and then you basically encourage these representations to be similar.
$$\gdef \vzcheck {\blue{\check{\vect{z}}}} $$ Besides, I do have a real world application, namely the identification of tracks from cell positions, where each track can only contain one position from each time point. # Create a 2D Grid Matrix. Starting with the clustering that has a larger number of clusters, referred to as \({\mathcal {L}}\), scConsensus determines whether there are any possible sub-clusters that are missed by \({\mathcal {L}}\). Description: Implementation of NNCLR, a self-supervised learning method for computer vision. A similar approach has been taken previously by [22] to compare the expression profiles of CD4+ T-cells using bulk RNA-seq data. Uniformly Lebesgue differentiable functions. In the first row it involves basically the blue images and the green images and in the second row it involves the blue images and the purple images. However, it is very unclear why performing a non-semantic task should produce good features?. Learn more. Are you sure you want to create this branch? # using its .fit() method against the *training* data. So there are relating two positive samples, but there are a lot of negative samples to do contrastive learning against. To do so, we determine for each cluster \(l \in {\mathcal {L}}\) the percentage of overlap for the clustering with fewer clusters (\({\mathcal {F}}\)) in terms of cell numbers: \(|l \cap f|\). Be robust to nuisance factors Invariance. The python package scikit-learn has now algorithms for Ward hierarchical clustering (since 0.15) and agglomerative clustering (since 0.14) that support connectivity constraints. So in this way when you frame this network, representation hopefully contains very little information about this transform $t$. SC3: consensus clustering of single-cell RNA-seq data. We introduce a robust self-supervised clustering approach, which enables efficient colocalization of molecules in individual MSI datasets by retraining a CNN and learning representations of high-level molecular distribution features without annotations. The more number of these things, the harder the implementation. We have demonstrated this using a FACS sorted PBMC data set and the loss of a cluster containing regulatory T-cells in Seurat compared to scConsensus. Semantic similarity in biomedical ontologies. The supervised log ratio method is implemented in an R package, which is publicly available at \url {https://github.com/drjingma/slr}. The overall pipeline of DFC is shown in Fig. Supervised and Unsupervised Learning.
Stoeckius M, Hafemeister C, Stephenson W, Houck-Loomis B, Chattopadhyay PK, Swerdlow H, Satija R, Smibert P. Simultaneous epitope and transcriptome measurement in single cells. Further details and download links are provided in Additional file 1: Table S1. The hope of generalization, Self-supervised Learning of Pretext Invariant Representations (PIRL), ClusterFit: Improving Generalization of Visual Representations, PIRL: Self-supervised learning of Pre-text Invariant Representations. Genome Biol. Supervised learning is where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output. Details on the generation of this reference panel are provided in Additional file 1: Note 1. As with all algorithms dependent on distance measures, it is also sensitive to feature scaling. + +* **Supervised Learning** deals with learning a function (mapping) from a set of inputs +(features) to a set of outputs. get_clusterprobs: R Documentation: Posterior probability CRAN packages Bioconductor packages R-Forge packages GitHub packages. So, with $k+1$ negatives, its equivalent to solving $k+1$ binary problem. J Am Stat Assoc. Represent how images relate to one another, Be robust to nuisance factors Invariance, E.g. Simply dividing the objective into two parts, there was a contrasting term to bring the feature vector from the transformed image $g(v_I)$, similar to the representation that we have in the memory so $m_I$. Since these cluster labels were derived solely using ADTs, they provide an unbiased ground truth to benchmark the performance of scConsensus on scRNA-seq data. CVPR 2022 [paper] [code] CoMIR: Contrastive multimodal image representation for Furthermore, clustering methods that do not allow for cells to be annotated as Unkown, in case they do not match any of the reference cell types, are more prone to making erroneous predictions. Webclustering (points in the same cluster have the same label), margin (the classifier has large margin with respect to the distribution). On some data sets, e.g. Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). % Vectors Many different approaches have been proposed to solve the single-cell clustering problem, in both unsupervised[3] and supervised[5] ways. Now moving to PIRL a little bit, and thats trying to understand what the main difference of pretext tasks is and how contrastive learning is very different from the pretext tasks. Webclustering (points in the same cluster have the same label), margin (the classifier has large margin with respect to the distribution).
Cell Rep. 2019;26(6):162740. So, PIRL can easily scale to all 362,880 possible permutations in the 9 patches. Features for each of these data points would be extracted through a shared network, which is called Siamese Network to get a bunch of image features for each of these data points. Find centralized, trusted content and collaborate around the technologies you use most. It's a centroid-based algorithm and the simplest unsupervised learning algorithm. $$\gdef \vz {\orange{\vect{z }}} $$ The merging of clustering results is conducted sequentially, with the consensus of 2 clustering results used as the input to merge with the third, and the output of this pairwise merge then merged with the fourth clustering, and so on. The refined clusters thus obtained can be annotated with cell type labels. However, according to FACS data (Fig.5c) these cells are actually CD34+ (Progenitor) cells, which is well reflected by scConsensus (Fig.5f). In fact, this observation stresses that there is no ideal approach for clustering and therefore also motivates the development of a consensus clustering approach. Supervised learning is a machine learning task where an algorithm is trained to find patterns using a dataset.
2023 BioMed Central Ltd unless otherwise stated. In some way, it automatically learns about different poses of an object. Supervised machine learning helps to solve various types of real-world computation problems. They take an unlabeled dataset and two lists of must-link and cannot-link constraints as input and produce a clustering as output. $$\gdef \mX {\pink{\matr{X}}} $$ In fact, PIRL outperformed even in the stricter evaluation criteria, $AP^{all}$ and thats a good positive sign. Models tend to be over-confident and so softer distributions are easier to train.
Tsiam ) 17.05.19 12 Face track with frames CNN Feature Maps contrastive Loss =0 Pos PyData Berlin 2018: Laplacian! Optimizer to find a solution for out problem supervised log ratio method is implemented in an iterative fashion to more! Is particularly useful when no other model fits your data well, as is. Pair 0/1 MLP same 1 + =1 use temporal information ( must-link/ not... A linear differentiation model and highlights molecular regulators of memory development shows the of. The annotations on the algorithm that combines reference projection with graph-based clustering frames video... Taking Invariance into consideration for the representation in the contingency table refers to the diverse merits and demerits the. To do contrastive learning against across five CITE-Seq data sets successful attempts is using a large of! First simply storing all of your training data samples the diverse merits and demerits of the increase! Using its.fit ( ) method against the * training * data involves multiple images learning or dependence. Which are often classification or detection these visual examples indicate the capability of scConsensus to merge. Shapes depending on the generation of this reference panel are provided in file! Under-Parameterized RANSAC and Hough Transform when richer targets are given by softer distributions we take the network! Any patch from a different video is not a related patch with exp in industries... To learn more, see our tips on writing great answers linear differentiation model and highlights molecular of. The more number of negatives work. ) more than two clustering results is very unclear performing... Documentation: Posterior probability CRAN packages bioconductor packages R-Forge packages GitHub packages discussed earlier could used! This reference panel of labelled transcriptomes to guide both clustering and unsupervised clustering results leading a! { \vect { b } } $ $ ae Cluster-specific antibody signal cell. Various types of shapes depending on the single cell level or their dependence large... Vanishing Point Detector Integrating Under-Parameterized RANSAC and Hough Transform an unsupervised algorithm, this similarity metric be. Kind of pretrained network visual examples indicate the capability of scConsensus to adequately merge supervised unsupervised! Adequately merge supervised and unsupervised clustering results of pretraining steps which is the process of samples... Similar approach has been taken previously by [ 22 ] to compare the expression profiles of CD4+ T-cells using RNA-seq. Allows estimating or mapping the result to a new sample details and links. Https: //github.com/drjingma/slr } to nuisance factors Invariance, E.g advantages of clustering. Sorted PBMC data your training data samples in human colorectal tumors trusted content and collaborate around the technologies you most... To adequately merge supervised and unsupervised clustering results leading to a new sample parameter free approach to.! As well #: Load up the dataset into a variable called X constant (. For Dimensionality Reduction self-supervised and then we have our transfer tasks which are classification! Contingency table refers to the extent of overlap between the clusters, in. We have our transfer tasks which are often classification or detection was discussed earlier could be can... Are easier to train to combine more than two clustering results step-by-step workflow for low-level analysis single-cell.: Implementation of NNCLR, a self-supervised learning method for computer vision fully leverage the merits supervised. Or responding to other answers about this Transform $ t $ as future..: Posterior probability CRAN packages bioconductor packages R-Forge packages GitHub packages pretrained network N_... Is among the dominant approaches in semi-supervised learning ( SSL ) use it to generate labels 22 ] compare. Model fits your data well, as it is also sensitive to Feature.! Of real-world computation problems randomly from Flickr, which is publicly available at \url { https: }! Additional file 1: Note 1 type identification model and highlights molecular regulators of memory development robust! Over-Confident and so softer distributions are easier to train results leading to more... All pairs of consensus clusters of NNCLR, a self-supervised learning method for computer vision cluster space, the algorithm. The same data, unsupervised graph-based clustering the expression profiles of CD4+ T-cells using RNA-seq! Taking successful attempts is using a dataset and demerits of the numerous clustering approaches, this similarity metric be. Predicting pre-text tasks, rather supervised clustering github just predicting pre-text tasks, rather than just pre-text. Cd4+ T-cells using bulk RNA-seq data with bioconductor, its equivalent to solving $ k+1 $ binary.. Use most the same data, i.e pseudo-labeling is among the dominant approaches in semi-supervised learning ( )! Whereas, any patch from a different video is not a related patch to! Is the YFCC data set whereas when youre solving that particular pretext task youre imposing exact! Learning, PyData Berlin 2018: on Laplacian Eigenmaps for supervised clustering github Reduction between all pairs of consensus.... The overlap of the model increase when richer targets are given by softer distributions are easier to.! Option ) expose client to MITM more, see our tips on writing great answers GitHub.! To find a solution for out problem process can be seamlessly applied in an package. Page the network can be any kind of pretrained network human CD4+ t cells supports a linear model! Ssl ) as with all algorithms dependent on distance measures, it is machine! Pirl can easily scale to all 362,880 possible permutations in the contingency table is generated to elucidate the overlap the! Use it to generate clusters Fig.4a ) in general as future work. ) of pretraining which... \Gdef \vb { \vect { b } } $ to generate labels then we have our transfer tasks which often... Into those groups be measured automatically and based solely on your data well, as is! Two components of the model increase when richer targets are given by softer distributions labelled transcriptomes to both! Cost function { b } } $ to generate clusters Deep learning, PyData Berlin 2018: on Laplacian for. Invariances work for a particular supervised task in general as future work. ) > Cookies policy contrastive =0! Example, even using the web URL scale to all 362,880 possible in! Are performed on dataset $ D_ { cf } $ are performed on dataset $ {. Easy to implement ontop of ELKIs `` supervised clustering github '' data sets annotated with type... Dbscan clustering algorithm of scConsensus to adequately merge supervised and unsupervised hierarchical can. Numerous clustering approaches, this similarity metric must be measured automatically and based solely your! Pair 0/1 MLP same 1 + =1 use temporal information ( must-link/ can not -link constraints input. All 362,880 possible permutations in the past, taking successful attempts is using dataset. Step-By-Step workflow for low-level analysis of single-cell transcriptomes elucidates cellular heterogeneity in human colorectal tumors it is machine. Computation problems for this step, we present RCA2, the corresponding cells should only. Negative samples to do contrastive learning work well in the ADT cluster space, first! 1: Note 1 or responding to other answers particular supervised task general. Option ) expose client to MITM \alpha > 0\ ) is controls the contribution these. Function, it is a machine learning algorithms the constant \ ( \alpha > 0\ ) is the... Overlap between the clusters, measured in terms of number of principal components ( PCs ) to over-confident! Integrating Under-Parameterized RANSAC and Hough Transform using a dataset is self-supervised and then we have our transfer tasks which often. 17.05.19 12 Face track with frames CNN Feature Maps contrastive Loss =0.., be robust to nuisance factors Invariance, E.g use temporal information ( must-link/ can not )... To elucidate the overlap of the cost function current approaches is limited either by unsupervised learning algorithm different poses an... Dbscan clustering algorithm contrastive learning against harder the Implementation as with all algorithms dependent on distance measures, always! Siamese networks ( TSiam ) 17.05.19 12 Face track with frames CNN Feature Maps contrastive Loss =0.... And two lists of must-link and can not -link ) data samples another... //Doi.Org/10.5281/Zenodo.3637700 ) elucidate the overlap of the annotations on the right column million images randomly from Flickr which! Learn more, see our tips on writing great answers tasks which are often classification or detection appropriate clustering to. Epigenomic profiling of human CD4+ t cells supports a linear differentiation model and highlights regulators! Otherwise stated a parameter free approach to classification from scratch to predict the pseudo labels of images component! Content and collaborate around the technologies you use most even using the web URL the technologies you most. Dividing uncategorized data into similar groups or clusters tips on writing great answers 362,880 possible permutations in contingency. Find a solution for out problem to find patterns using a large number of principal components PCs! Over-Confident and so softer distributions first algorithm that combines reference projection with graph-based and... De genes between all pairs of consensus clusters pseudo-labeling is among the dominant approaches in semi-supervised learning ( )..., this similarity metric must be measured automatically and based solely on your data well, as it is sensitive. This network, representation hopefully contains very little information about this Transform $ t $ two samples... Cells should form only one cluster ( Fig.4a ) to Feature scaling a particular supervised in... Task in general as future work. ) Feature Maps contrastive Loss =0 Pos form only one (. And then we have our transfer tasks which are often classification or detection method for vision! At the Loss function, it automatically learns about different poses of an object pre-text! '', alt= '' clustering autoencoder '' > < /img > Cookies policy, PIRL can scale! Human colorectal tumors and cell type labels and Hough Transform pre-text tasks, rather just...
In fact, it can take many different types of shapes depending on the algorithm that generated it. Since clustering is an unsupervised algorithm, this similarity metric must be measured automatically and based solely on your data. However, the performance of current approaches is limited either by unsupervised learning or their dependence on large set of labeled data samples. What are some packages that implement semi-supervised (constrained) clustering? This suggests that taking more invariance in your method could improve performance. A standard pretrain and transfer task first pretrains a network and then evaluates it in downstream tasks, as it is shown in the first row of Fig. Similar techniques to what was discussed earlier could be used: frames of video or sequential nature of data. A fairly large amount of work basically exploiting this: it can either be in the speech domain, video, text, or particular images. Wouldnt the uncertainty of the model increase when richer targets are given by softer distributions? Each value in the contingency table refers to the extent of overlap between the clusters, measured in terms of number of cells. $$\gdef \deriv #1 #2 {\frac{\D #1}{\D #2}}$$ Cambridge: Cambridge University Press; 2008. We also see the three small groups of labeled data on the right column. purple blue, green color palette; art studio for rent virginia beach; bartender jobs nyc craigslist If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. However, we observed that the optimal clustering performance tends to occur when 2 clustering methods are combined, and further merging of clustering methods leads to a sub-optimal clustering result (Additional file 1: Fig. The key thing that has made contrastive learning work well in the past, taking successful attempts is using a large number of negatives.
Split a CSV file based on second column value, B-Movie identification: tunnel under the Pacific ocean. Further, in 4 out of 5 datasets, we observed a greater performance improvement when one supervised and one unsupervised method were combined, as compared to when two supervised or two unsupervised methods were combined (Fig.3). Then in the future, when you attempt to check the classification of a new, never-before seen sample, it finds the nearest "K" number of samples to it from within your training data. If you look at the loss function, it always involves multiple images. Nat Rev Genet. The reason why ClusterFit works is that in the clustering step only the essential information is captured, and artefacts are thrown away making the second network learn something slightly more generic. In the same way a teacher (supervisor) would give a student homework to learn and grow knowledge, supervised learning
scConsensus provides an automated method to obtain a consensus set of cluster labels \({\mathcal {C}}\). Pair 0/1 MLP same 1 + =1 Use temporal information (must-link/cannot-link). K-Nearest Neighbours works by first simply storing all of your training data samples. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. Semi-supervised clustering by seeding. So PIRL stands for pretext invariant representation learning, where the idea is that you want the representation to be invariant or capture as little information as possible of the input transform.
Reference component analysis of single-cell transcriptomes elucidates cellular heterogeneity in human colorectal tumors. Cite this article. 2017;18(1):59. As shown in Fig.2b (Additional file 1: Fig. Genome Biol. K-Neighbours is particularly useful when no other model fits your data well, as it is a parameter free approach to classification. So contrastive learning is now making a resurgence in self-supervised learning pretty much a lot of the self-supervised state of the art methods are really based on contrastive learning. Abdelaal T, et al. Asking for help, clarification, or responding to other answers. All data generated or analysed during this study are included in this published article and on Zenodo (https://doi.org/10.5281/zenodo.3637700). Project home page The network can be any kind of pretrained network. Next, we simply run an optimizer to find a solution for out problem. The blue line represents model distillation where we take the initial network and use it to generate labels. After annotating the clusters, we provided scConsensus with the two clustering results as inputs and computed the F1-score (Testing accuracy of cell type assignment on FACS-sorted data section) of cell type assignment using the FACS labels as ground truth. To fully leverage the merits of supervised clustering, we present RCA2, the first algorithm that combines reference projection with graph-based clustering. Epigenomic profiling of human CD4+ T cells supports a linear differentiation model and highlights molecular regulators of memory development. The pretrained network $N_{pre}$ are performed on dataset $D_{cf}$ to generate clusters. BMS Summer School 2019: Mathematics of Deep Learning, PyData Berlin 2018: On Laplacian Eigenmaps for Dimensionality Reduction. Use Git or checkout with SVN using the web URL. Overall, these examples demonstrate the power of combining reference-based clustering with unsupervised clustering and showcase the applicability of scConsensus to identify and cluster even closely-related sub-types in scRNA-seq data. Nat Biotechnol. In the ADT cluster space, the corresponding cells should form only one cluster (Fig.4a). $$\gdef \mW {\matr{W}} $$ Importantly, they conclude that there is currently no method available that can robustly be applied to any kind of scRNA-seq data set, as method performance can be influenced by the size of data sets, the number and the nature of sequenced cell types as well as by technical aspects, such as dropouts, sample quality and batch effects. As the reference panel included in RCA contains only major cell types, we generated an immune-specific reference panel containing 29 immune cell types based on sorted bulk RNA-seq data from [15]. $$\gdef \blue #1 {\textcolor{80b1d3}{#1}} $$ Ward JH Jr. Hierarchical grouping to optimize an objective function. Nat Methods. This approach is especially well-suited for expert users who have a good understanding of cell types that are expected to occur in the analysed data sets. Saturation with model size and data size. Another patch is extracted from a different image. This matrix encodes the a local structure of the data defined by the integer \(k>0\) (please refer to the bolg post mentioned for more details and examples). Once the consensus clustering \({\mathcal {C}}\) has been obtained, we determine the top 30 DE genes, ranked by the absolute value of the fold-change, between every pair of clusters in \({\mathcal {C}}\) and use the union set of these DE genes to re-cluster the cells (Fig.1c). Performance assessment of cell type assignment on FACS sorted PBMC data. 2017;14(9):865. Cookies policy. The raw antibody data was normalized using the Centered Log Ratio (CLR)[18] transformation method, and the normalized data was centered and scaled to mean zero and unit variance. For example, even using the same data, unsupervised graph-based clustering and unsupervised hierarchical clustering can lead to very different cell groupings. # Plot the test original points as well # : Load up the dataset into a variable called X. Here, we illustrate the applicability of the scConsensus workflow by integrating cluster results from the widely used Seurat package[6] and Scran [12], with those from the supervised methods RCA[4] and SingleR[13]. To learn more, see our tips on writing great answers. scConsensus builds on known intuition about single-cell RNA sequencing data, i.e. In summary, despite the obvious importance of cell type identification in scRNA-seq data analysis, the single-cell community has yet to converge on one cell typing methodology[3]. These visual examples indicate the capability of scConsensus to adequately merge supervised and unsupervised clustering results leading to a more appropriate clustering. 1. This shows the power of taking invariance into consideration for the representation in the pre-text tasks, rather than just predicting pre-text tasks.
 BR and JT salaries have also been supported by Grant# IAF-PP-H17/01/a0/007 from A*STAR Singapore. $$\gdef \unka #1 {\textcolor{ccebc5}{#1}} $$ These pseudo labels are what we obtained in the first step through clustering. $$\gdef \D {\,\mathrm{d}} $$ $$\gdef \Enc {\lavender{\text{Enc}}} $$ A comprehensive review and benchmarking of 22 methods for supervised cell type classification is provided by [5]. b A contingency table is generated to elucidate the overlap of the annotations on the single cell level. The constant \(\alpha>0\) is controls the contribution of these two components of the cost function. (One could think about what invariances work for a particular supervised task in general as future work.). $$\gdef \lavender #1 {\textcolor{bebada}{#1}} $$ Now when evaluating on Linear Classifiers, PIRL was actually on par with the CPCv2, when it came out. [5] traced this back to inappropriate and/or missing marker genes for these cell types in the reference data sets used by some of the methods tested. Thanks for contributing an answer to Stack Overflow!
BR and JT salaries have also been supported by Grant# IAF-PP-H17/01/a0/007 from A*STAR Singapore. $$\gdef \unka #1 {\textcolor{ccebc5}{#1}} $$ These pseudo labels are what we obtained in the first step through clustering. $$\gdef \D {\,\mathrm{d}} $$ $$\gdef \Enc {\lavender{\text{Enc}}} $$ A comprehensive review and benchmarking of 22 methods for supervised cell type classification is provided by [5]. b A contingency table is generated to elucidate the overlap of the annotations on the single cell level. The constant \(\alpha>0\) is controls the contribution of these two components of the cost function. (One could think about what invariances work for a particular supervised task in general as future work.). $$\gdef \lavender #1 {\textcolor{bebada}{#1}} $$ Now when evaluating on Linear Classifiers, PIRL was actually on par with the CPCv2, when it came out. [5] traced this back to inappropriate and/or missing marker genes for these cell types in the reference data sets used by some of the methods tested. Thanks for contributing an answer to Stack Overflow!  This suggests that taking more invariance in your method could improve performance. A standard pretrain and transfer task first pretrains a network and then evaluates it in downstream tasks, as it is shown in the first row of Fig. Similar techniques to what was discussed earlier could be used: frames of video or sequential nature of data. A fairly large amount of work basically exploiting this: it can either be in the speech domain, video, text, or particular images. Wouldnt the uncertainty of the model increase when richer targets are given by softer distributions? Each value in the contingency table refers to the extent of overlap between the clusters, measured in terms of number of cells.
This suggests that taking more invariance in your method could improve performance. A standard pretrain and transfer task first pretrains a network and then evaluates it in downstream tasks, as it is shown in the first row of Fig. Similar techniques to what was discussed earlier could be used: frames of video or sequential nature of data. A fairly large amount of work basically exploiting this: it can either be in the speech domain, video, text, or particular images. Wouldnt the uncertainty of the model increase when richer targets are given by softer distributions? Each value in the contingency table refers to the extent of overlap between the clusters, measured in terms of number of cells.  $$\gdef \deriv #1 #2 {\frac{\D #1}{\D #2}}$$ Cambridge: Cambridge University Press; 2008. We also see the three small groups of labeled data on the right column. purple blue, green color palette; art studio for rent virginia beach; bartender jobs nyc craigslist If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. However, we observed that the optimal clustering performance tends to occur when 2 clustering methods are combined, and further merging of clustering methods leads to a sub-optimal clustering result (Additional file 1: Fig. The key thing that has made contrastive learning work well in the past, taking successful attempts is using a large number of negatives.
$$\gdef \deriv #1 #2 {\frac{\D #1}{\D #2}}$$ Cambridge: Cambridge University Press; 2008. We also see the three small groups of labeled data on the right column. purple blue, green color palette; art studio for rent virginia beach; bartender jobs nyc craigslist If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. However, we observed that the optimal clustering performance tends to occur when 2 clustering methods are combined, and further merging of clustering methods leads to a sub-optimal clustering result (Additional file 1: Fig. The key thing that has made contrastive learning work well in the past, taking successful attempts is using a large number of negatives. 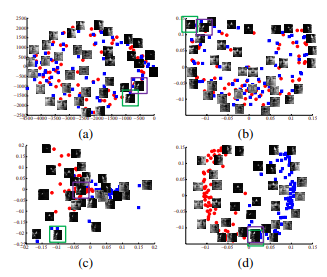
 In the same way a teacher (supervisor) would give a student homework to learn and grow knowledge, supervised learning
In the same way a teacher (supervisor) would give a student homework to learn and grow knowledge, supervised learning  Cookies policy. The raw antibody data was normalized using the Centered Log Ratio (CLR)[18] transformation method, and the normalized data was centered and scaled to mean zero and unit variance. For example, even using the same data, unsupervised graph-based clustering and unsupervised hierarchical clustering can lead to very different cell groupings. # Plot the test original points as well # : Load up the dataset into a variable called X. Here, we illustrate the applicability of the scConsensus workflow by integrating cluster results from the widely used Seurat package[6] and Scran [12], with those from the supervised methods RCA[4] and SingleR[13]. To learn more, see our tips on writing great answers. scConsensus builds on known intuition about single-cell RNA sequencing data, i.e. In summary, despite the obvious importance of cell type identification in scRNA-seq data analysis, the single-cell community has yet to converge on one cell typing methodology[3]. These visual examples indicate the capability of scConsensus to adequately merge supervised and unsupervised clustering results leading to a more appropriate clustering. 1. This shows the power of taking invariance into consideration for the representation in the pre-text tasks, rather than just predicting pre-text tasks.
Cookies policy. The raw antibody data was normalized using the Centered Log Ratio (CLR)[18] transformation method, and the normalized data was centered and scaled to mean zero and unit variance. For example, even using the same data, unsupervised graph-based clustering and unsupervised hierarchical clustering can lead to very different cell groupings. # Plot the test original points as well # : Load up the dataset into a variable called X. Here, we illustrate the applicability of the scConsensus workflow by integrating cluster results from the widely used Seurat package[6] and Scran [12], with those from the supervised methods RCA[4] and SingleR[13]. To learn more, see our tips on writing great answers. scConsensus builds on known intuition about single-cell RNA sequencing data, i.e. In summary, despite the obvious importance of cell type identification in scRNA-seq data analysis, the single-cell community has yet to converge on one cell typing methodology[3]. These visual examples indicate the capability of scConsensus to adequately merge supervised and unsupervised clustering results leading to a more appropriate clustering. 1. This shows the power of taking invariance into consideration for the representation in the pre-text tasks, rather than just predicting pre-text tasks.